

If you're like me you probably have a few folders or drives on your computer, home server, or NAS that you keep around "just in case" but rarely find the need to access those files so they just end up taking up space right? Well for me, those drives were a 4x4TB RAID5 volume with 6.1TB of gameplay recordings spanning from 2017 until now that I didn't want to part with, but I didn't want to keep locally because I have more important things that need that storage (mainly my ever growing DVD/Blu-ray collection that I'm backing up to my Plex server).
So I found myself faced with a lot of options to handle this sizeable amount of data I wanted to keep. I could have bought a 10TB hard drive for $90 and kept it in a drawer somewhere or I could have upgraded my Synology NAS. Both options seemed like a good choice for me but as I started looking at the costs I found myself visiting cloud storage calculators to see what it would cost me to store the same amount of storage for X months/years.
AWS S3 Glacier seemed to fit my needs with the billing calculator estimating about $6.12 per month for 6.1TB of data (we'll see how accurate that is after all of the data is uploaded and sitting there for a few months). For the cost of a single 10TB hard drive I can host the data for about 14 months which is a good solution for now and buys me some time to I decide what to do with my current setup at home.
I went with Glacier's "Deep Archive" for maximum cost savings, but it does have some drawbacks though:
- Slow recovery time - If I need to restore a file it could take 24+ hours for the file(s) to "warm up" and become available.
- Expensive restores - The cost to backup 1TB is about $1, but the cost to restore that 1TB is about $20.
- Early deletion fees - Data deleted within 180 days of upload will result in an additional fee for the remaining time of that 180 days.
- Slowish backups - Currently my upload speed is being capped at 12MB/s, if I start a second process it gets capped at the same speed so this is being throttled on the AWS side.
I was going to put a 4th point on there, but this one isn't specific to Glacier and just a general issue with AWS as a whole: it's all very confusing the first time. When you create an account with AWS and want to use Glacier, your first instinct is to probably search for "Glacier" as a service, but that brings you to "AWS Glacier" which is different than "AWS S3 Glacier" which isn't even a service, it's a "storage class" of S3. So how do you actually use it? Let's get right into the absolute easiest way to backup your data to Glacier!
Creating an S3 Bucket
- Login to the AWS Console and search for S3 then navigate to it.
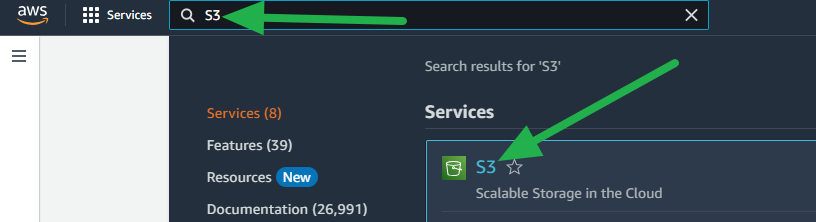
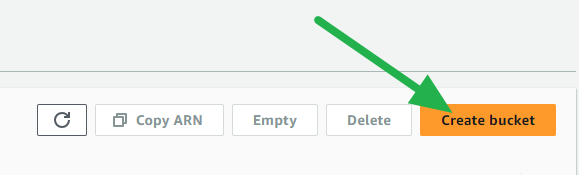
- Click on the Create bucket button.
- Name your S3 bucket something unique, the rest of the settings can be left default for the lowest cost or you can adjust as needed.
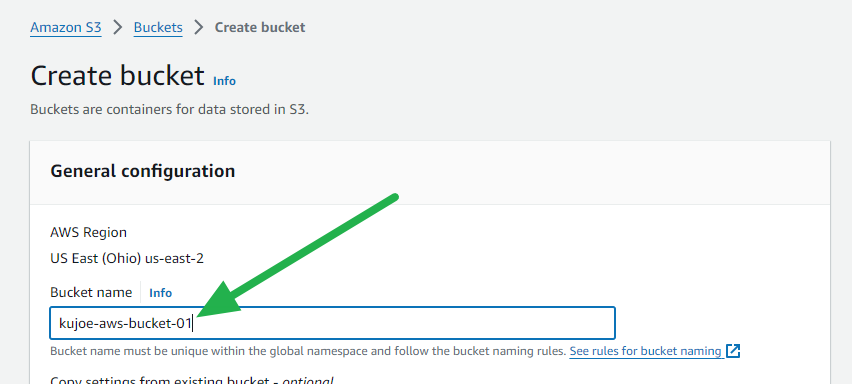
- Scroll all the way down and click on the Create bucket button.

And that's all of the steps for creating the bucket in AWS, you should now see your new bucket here:
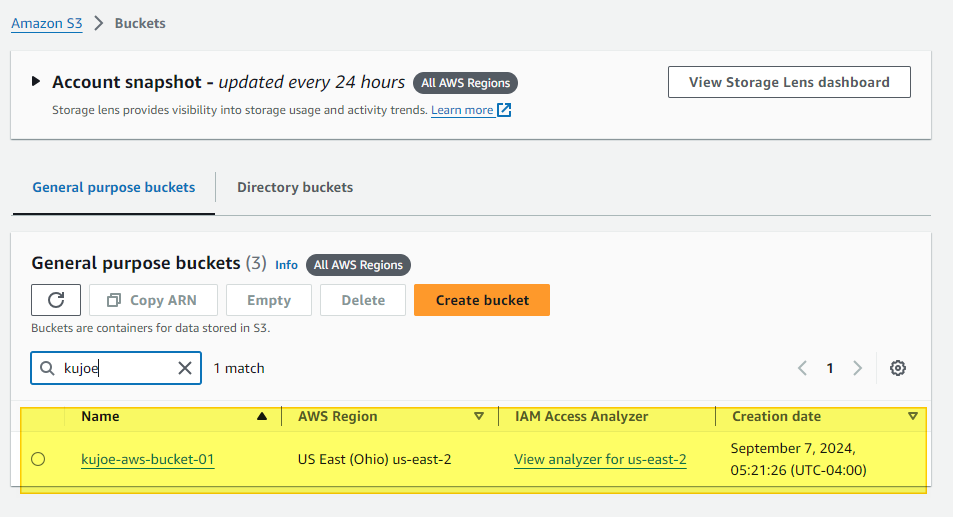
Create a new S3 User
- Login to the AWS Console and search for IAM then navigate to it.
- Navigate to Users.
- Click on the Create user button.
- Enter a username and click the Next button.
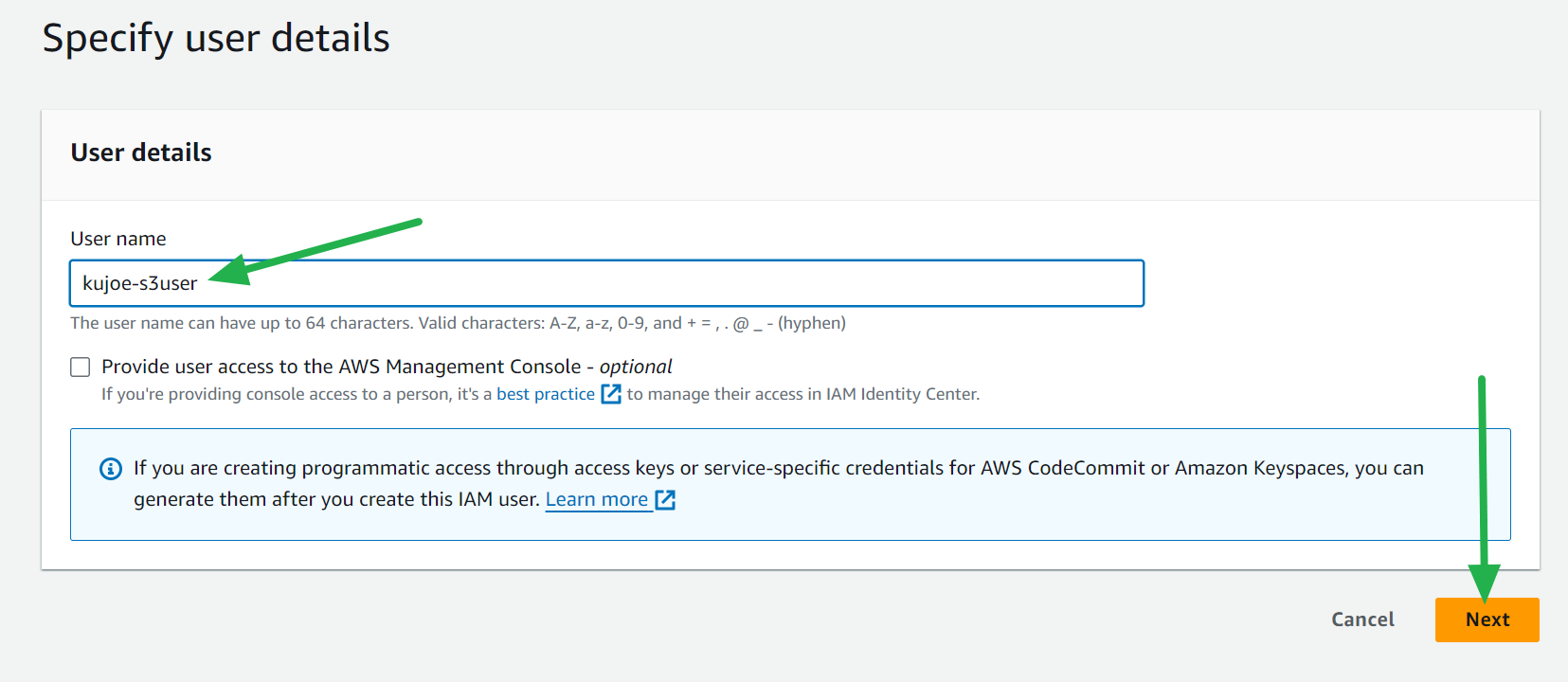
- Select Attach policies directly and select AmazonS3FullAccess then click the Next button.
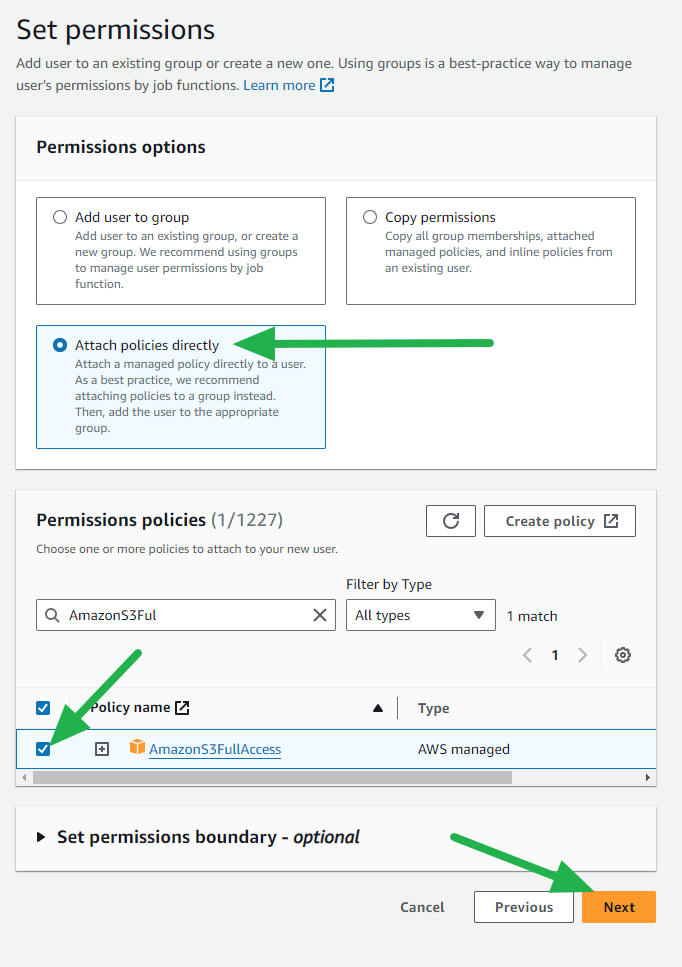
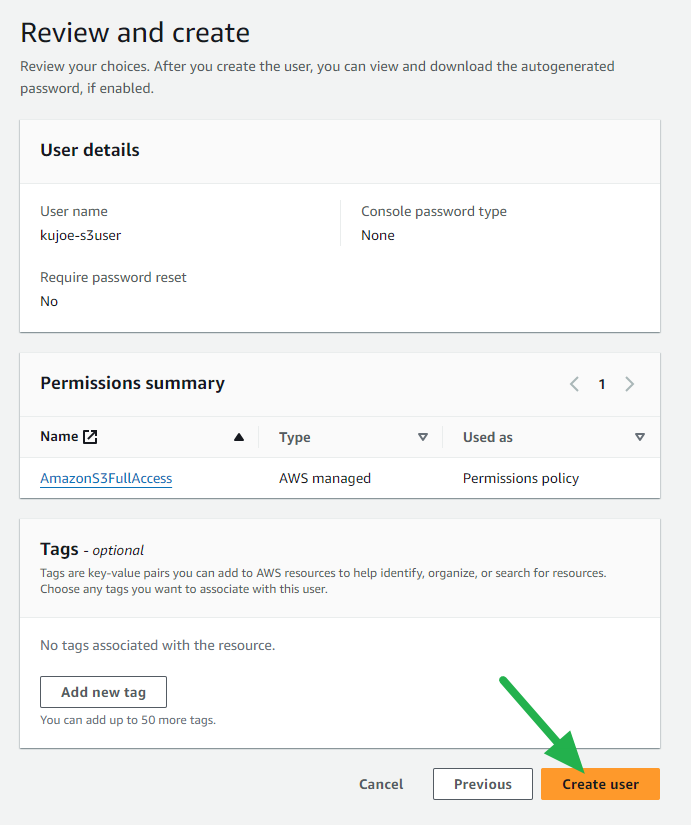
- Review and click the Create user button.
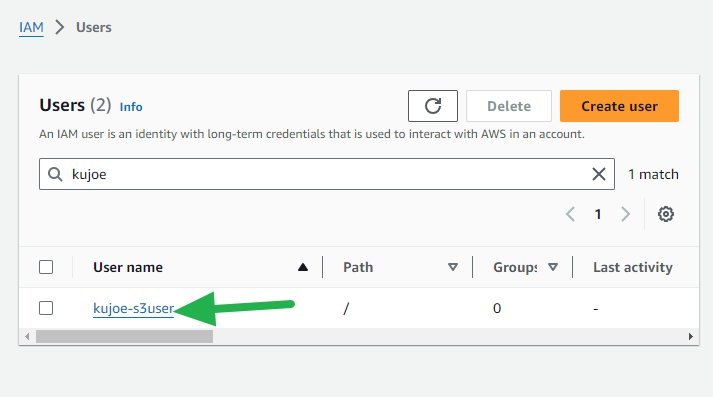
- Click on the new user from the list.
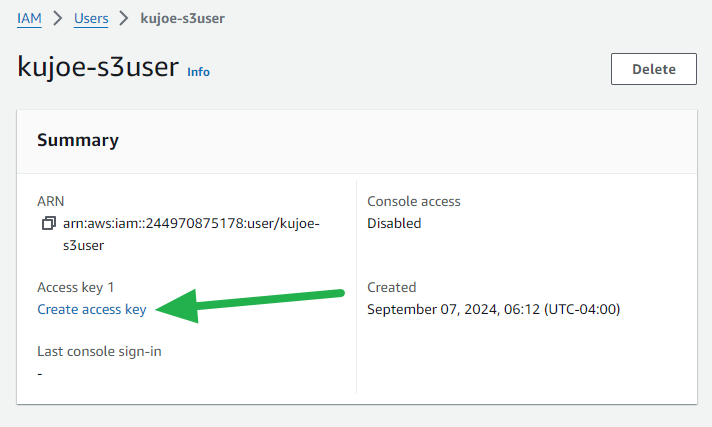
- Click on Create access key.
- Select Command Line Interface (CLI) and check the Confirmation box, then click the Next button.
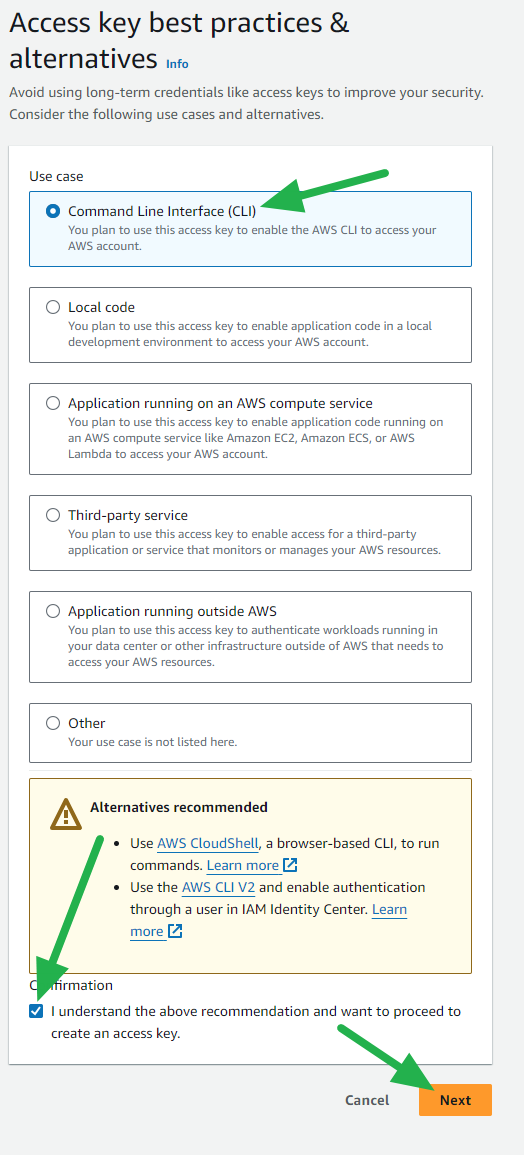
- Enter a description if you'd like and click the Create access key button.
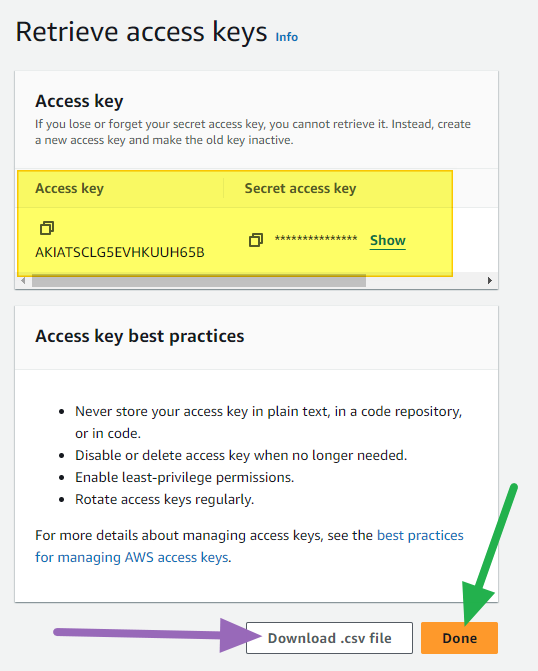
- Record your Access key and Secret access key (downloading the CSV is recommended) and then click the Done button.
Now that you have a user created, you're ready to start backing up your data!
Backing up to AWS S3 Glacier Deep Archive
- Before you proceed you'll want to install the AWS CLI tool on your PC.
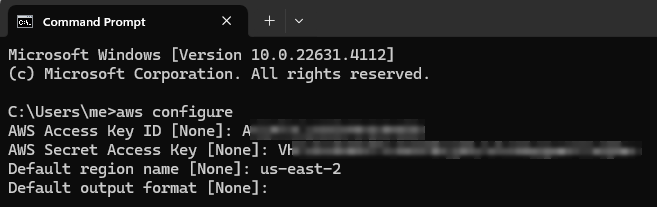
Now open up Command Prompt and enter the following command to fill out the fields with your new access keys and default region:
aws configure
Run this command (replacing LOCAL_DIRECTORY and S3_BUCKET):
aws s3 sync LOCAL_DIRECTORY s3://S3_BUCKET --storage-class DEEP_ARCHIVE
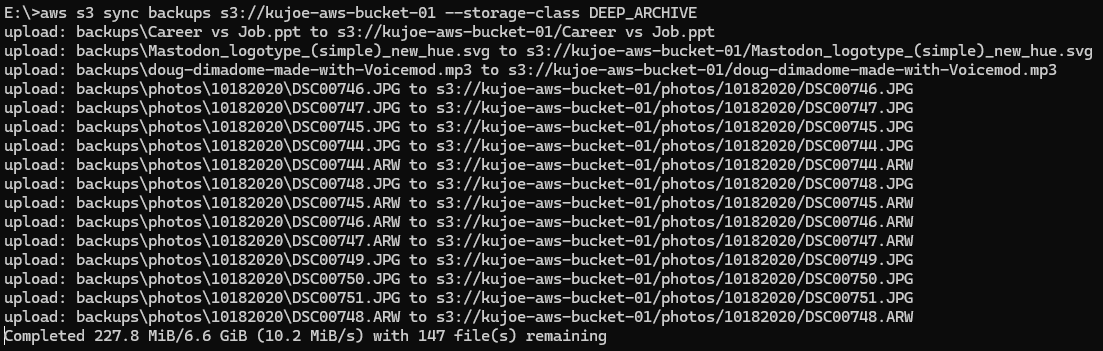
And that's it! Once you run the aws configure command your credentials will be saved in the C:\Users\USERNAME\.aws\ directory if you need to change or grab the details later. Once it's saved, you don't need to run that command for future syncs even with different buckets.
Hopefully this saves you some local disk space and money! Be sure you check our my previous posts to configure billing alerts to prevent your costs from growing out of control!
- Create a budget in AWS
- Create a Cost Anomaly Detection Monitor in AWS
- Using AWS CloudWatch to monitor estimated charges
Happy Clouding!
Go out and do good things!
-KuJoe